MS SQL server performance tuning
2021-10-02
ehk eesti keeles SQL serveri jõudluse optimeerimine.
Mis on oluline ja mis mitte?
Kui võtta suvaline SQL server, millel on jõudlusega probleeme, siis millest alustada? Kas riistvara, millel server töötab on oluline - loomulikult. Aga see, kuidas SQL server on installeeritud - kas vaike või kohandatud sätetega - aga loomulikult. Kas SQL-i haldustööd, näiteks indeksite hooldamine, on väga oluline teema? Aga kuipalju need tegurid reaalselt ka mõjutavad jõudlust? Kas see, kui nt Adhoc ei ole sisse lülitatud, kas selle mõju on 1% või 10%? Kas keegi DBA-dest seda üldse mõõdab? Mina ei ole mõõtnud, kuna selle mõõtmine on keeruline, sest ma ei tea enamasti milliseid päringuid serveris käivitatakse. Või kui indeksid on fragmenteerunud. Kui teha indeksite korrastamist siis kas siis lõppkasutaja seda märkab? Enamasti mitte. Ja kui märkab, siis seda suure tõenäosusega ei põhjustanud mitte indeksite fragmenteerumine, vaid indeksite korrastamisega toimunud kõrvaltulemid - nt halva päringuplaani kustutamine, või indeksi statistika uuendamine, mis võimaldas genereerida täpsema päringu plaani. Ehk siis kuidas leida üles need paar kolm muudatust, mida ka lõppkasutaja märkaks?
Minu enda viimase aja kogemus on, et parima tulemuse saavutab indeksite haldamise, päringute optimeerimise ja õigete andmetüüpide valimisega. Kui esimese punktiga saab suures plaanis üksinda hakkama, siis kahe järgmise tegevusega on oluline koostöö rakenduse arendajatega.
Indeksid
Indeksite fragmenteerumine
Eelpool mainisin indeksite fragmenteerumist. Kas see siis on oluline? Nii ja naa. St et jah. Indeksite fragmenteerumisega peab tegelema. Küsimus on, et kui tihti ja millises mahus. Aga milles fragmenteerumise probleem seisneb? Vanasti, kui serveris oli vähe mälu ja enamus andmeid oli kettal, ning kui kasutati pöörlevaid kettaid, siis andmete lugemine kettalt võttis aega, kui andmed ei olnud nn järjest. Aga hetkel kui enamasti kasutame SSD kettaid ja serveris on palju mälu, siis kui suur on kiiruse erinevus andmete lugemisel kui andmeid on järjest või andmed ei ole järjest? See vahe ei ole tegelikult enam märkimisväärne. Seega fragmenteerumise mõju ei ole enam nii oluline. Küll aga indekste korrastamise (index rebuild või index reorganize) tegevuse järel korrastatakse tabelites olevate andmete statistikad. Ja see on märgatavalt olulisem. Kuna statistikate alusel toimub päringu plaani koostamine. Samas Indeksite statistikaid võib uuendada ka indekseid korrastamata.
Puuduvad indeksid
Indeksite fragmenteerumisest tunduvalt olulisem on õiged indeksid. Indeksid mis aitavad päringul võimalikult kiiresti vastust saada. Nt kui otsitakse isiku nime, aga nime väljal puudub indeks ehk kui otsitaval väljal indeks puudub on vajalik terve tabeli skaneerimine ja see on aja ja ressursi mahukas toiming. Ja see on koht, kus hea indeks võib muuta päringu 100x või 1000x kiiremaks. Aga kui indeksid muudavad päringud kiiremaks, siis miks mitte teha indeksid kõikidele väljadele? Teoorias võib. Aga ainult sellisel juhul, kui seda tabelit enam ei muudeta. Sest kui hakkame andmeid muutma, siis tuleb ka indeksites andmeid muuta. Ja see võib muutmise päringu aeglaseks muuta. Ja teiseks kui meil on indeksid kõikide väljade kohta, aga päringud ei vaja neid? Siis me lihtsalt koormame andmebaasi kasutu andmemahuga ja siit jõuame järgmise olulise punkti juurde.
Üleliigsed indeksid
Kui puuduvad indeksid võivad oluliselt mõjutada päringute kiirust, siis ka üleliigsed indeksid võivad mõjutada oluliselt päringute kiirust. Aga eelkõige päringuid, kus midagi muudetakse. Põhjus peitub selles, et andmete muutumisel tuleb korrastada andmed ka indeksis. Näitena, kui meil on tabel 20-ne väljaga ja iga välja kohta on oma indeks, siis ühe kirje kustutamisel tuleb andmed kustutada ka kõigis indeksites.
Vähe või üldse mitte kasutatavate indeksi(te) kustutamisega tuleb aga olla ettevaatlik. Probleemid millega võib siin kokku puutuda on, et indeksi nimi on mingisse päringusse sisse kirjutatud - mis iseenesest on paha, kuna SQL peaks saama alati ise otsustada, millist indeksit ta kasutab. Teine probleem võib olla tarkvara uuendamisega mis siis kontrollib indeksi olemasolu ja kui ta indeksit ei leia, siis katkestab uuenduse.
Indeksite informatsioon
SQL server omab infot selle kohta kui palju indekseid on kasutatud. Aga siin tuleb meeles pidada, et see info läheb kaduma niipea kui serverit restarditakse. Seega kui hakata otsustama indeksi kasulikkuse üle võiks server olla juba vähemalt nädala jagu töötanud. Sama on puuduvate indeksite informatsiooniga, mida SQL server kogub. Kahjuks aga ei ole need soovitused enamasti kõige paremad. Need on head esmaseks sisendiks, et siia võiks indeksi lisada, aga millised väljad indeksisse lisada - see vajab enamasti põhjalikumat analüüsimist. Lihtsamaks teeb analüüsi see, kui on teada millist päringut puuduva indeksi soovitus puudutab.
Päringud
Milline on hea milline on halb päring? Sellele ei saa üheselt vastata - kui on soov saada terve baasi sisu ühele raportile ja seal on sadu ja sadu kirjeid, siis selline päring ongi aeglane. Aga kas see on ka halb - see on ise küsimus. Küll aga on oluline, teada millisel juhul tehakse tabelile scan ja millal seek. Mitte et scan oleks paha ja seek hea. Aga kui päring ise välistab seek-i kasutamise. Siis võiks mõelda, kas päring sellisel kujul on tõesti vajalik. Nt kui otsitakse kasutaja nime
select * from users where name like '%@muutuja%'
siis kui suur on tõenäosus et nime algust ei teata ja otsima hakatakse nt nime teisest või kolmandast tähest. Ehk kui lubame kitsendust et alati otsitakse esimesest tähest, siis efektiivsema päringu saab kui päring näeb välja järgmine:
select * from users where name like '@muutuja%'
Vahe on küll ainult ühes % -i märgis aga kui väljal "name" on indeks, siis esimene teeb indeksil full scan-i ja teise päringu puhul toimub index seek ja see on kordades kiirem.
Selliseid näiteid võib tuua veel ja veel, kus väikeste päringu kitsendustega saavutab väga olulise jõudluse kokkuhoiu. See aga eeldab koostööd DBA, arendaja ja rakenduse kasutaja vahel.
Eraldi teema on päringud, mille puhul päringu plaani koostamisel võetakse aluseks tabeli struktuur ja selle põhjal arvutatakse mälu vajadus, mida päringu täitmisel vaja läheb. Ehk siit jõuame järgmise teema juurde - andmebaasi disain.
Disain
Täna on serveris enamasti palju mälu ja kiired kettad. Ja jõudluse optimeerimisele ei pöörata enamasti nii suurt tähelepanu. Kui on probleem, siis lisame riistvara. Aga samas miks mitte teha SQL-il päringute plaani koostamist kergemaks. Kui tabeli väljas kasutatakse maksimum 10 tähemärgilist sümbolit, siis ei ole mõistlik sinna reserveerida 100 tähemärki. Või hoopis nvarchar(max)-i! SQL server saab sellega hakkama, aga sellisel juhul ei tasu oodata, et SQL teeb parima võimaliku plaani päringu lahendamiseks. Ka turvalisuse puhul me enamasti anname minimaalsed õigused, mida kasutaja vajab. Sama võiks kehtida siin - anname minimaalse andmete reserveerimise võimaluse ja kui selgub, et välja on vaja muuta, siis alles muudame.
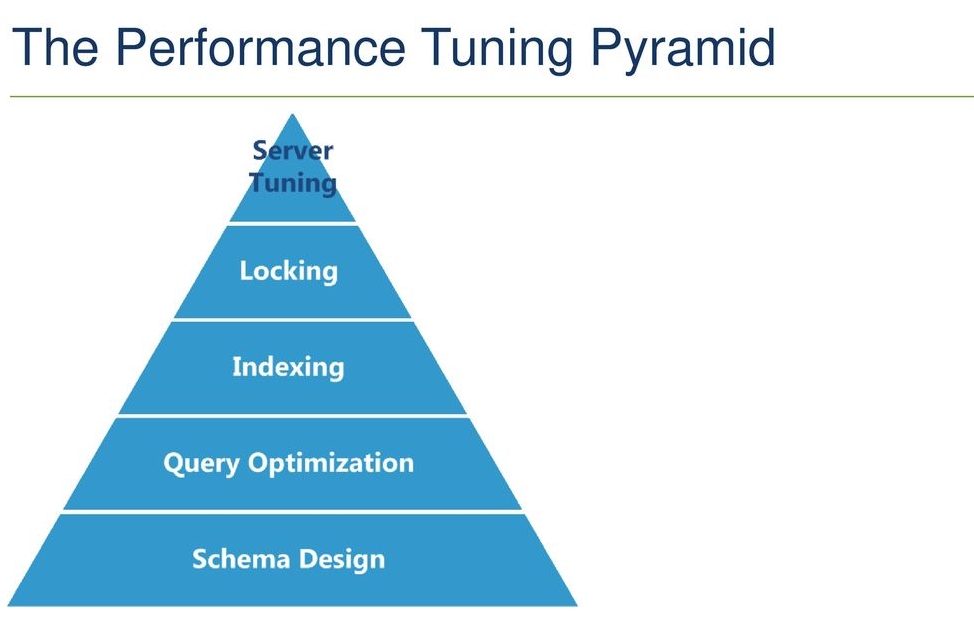
Kokkuvõtte
Leidsin internetist sellise ilusa jõudlust ilmestava püramiidi. Küsimus on et mida on kõige lihtsam muuta, et saadav kasu oleks suurim? Kui riistvara muuta on suhteliselt lihtne, samas on selle kasutegur väike. Baasi disaini muuta keeruline, samas kasutegur võib olla kõige suurem. Indeksid ja päringud jäävad keskele - neid enamasti on suhteliselt lihtsasti võimalik muuta ja sinna tasuks optimeerimise puhul minu arvates kõige rohkem DBA-l panustada.